![]()
Z02: INFormation, INFormatics, and INFrastructure

Projects of the CRC 1768
Z02: INFormation, INFormatics, and INFrastructure
Central activities of the CRC VirusREvolution
Routine processing of raw data from high-throughput sequencing, spectral, and imaging technologies through standardised data analysis tools and pipelines is vital for the comparability and reproducibility of results. However, the use of such tools and pipelines demands a detailed understanding of the signals in the data as well as associated variations, artefacts, and noise. Here, we apply our expertise to preprocess, analyse, integrate, and disseminate the wide range of high-throughput and -dimensional datasets generated and gathered within this CRC. Further, our project addresses the critical issue of accurate description, management, storing, and sharing of scientific data and software, as well as ensuring the reproducibility of obtained results. We build on current efforts from the relevant NFDI consortia in which the PIs of the CRC VirusREvolution are strongly involved, i.e., M. Marz (A04) as co-speaker and N. Cassman (Z02) in NFDI4Microbiota, B. König-Ries (Z02) as co-speaker in NFDI4Biodiversity, T. Figge (C03) as co-speaker in NFDI4Bioimage, and R. Gerlach (Z02) of the research data management team coordinating and supporting NFDI activities at FSU Jena.
Overview of the Z02 INF project plan.
For example, as outlined below, NFDI-supported tools and repositories will be used as appropriate. In the following, we describe the state of the art and our own preliminary work in three key fields for this project: data management, bioinformatics services, and data integration.
a. Data management – state of the art. For more than a decade, a cultural change has been taking place in the handling of scientific results. This is primarily about greater transparency in research processes and better traceability and reusability of results. In addition to the traditional publication of results in a scientific journal or book, data, software, and other materials generated in the course of research activities are increasingly being prepared and published in a way that enables broad reuse by science, industry, and the general public. This development goes along with the digitalisation of research, which on the one hand is constantly expanding the possibilities of data generation, data processing, and data exchange. On the other hand it requires an ever-increasing use of human, technical, and monetary resources in the development of technical solutions and the establishment of infrastructure. Individual institutions are often no longer able to meet these requirements. Therefore numerous national and international initiatives and projects have been established, such as the National Research Data Infrastructure (NFDI), the European Open Science Cloud (EOSC), Gaia-X, GÉANT, or the Research Data Alliance (RDA), and the Society of Research Software Engineering (RSE), to develop standards, best practices, and services to support and promote cultural change.
In recent years, public research funders, above all the European Commission, have expanded their requirements and now expect compliance with and implementation of open science principles, such as open access publications, open source code, or open data. The German Research Foundation (DFG) has also redefined its expectations with the “Guidelines for Safeguarding Good Scientific Practice” code published in 2019 and has specified them in particular in the area of data management. There are similar developments among publishers, who increasingly expect all materials (including data and code) on which a publication is based to be documented accordingly and made publicly accessible. Recommendations and guidelines are also published by professional associations and research institutions. For example, the FSU Jena has had a guideline and recommendation for handling research data since 2016 (zedif).
In large, data-intensive collaborative projects, it has been shown that centrally organised data management contributes significantly to the success of a project. The data management team often implements and operates the necessary technical infrastructure for data storage and exchange. It curates data to ensure quality and fulfil the requirements of the above-mentioned stakeholders. It supports researchers in using the infrastructure together with the project participants. It develops policies and recommendations for uniform and sustainable data management in the project. Examples of this are the data management in the DFG priority programme Biodiversity Exploratories or the Jena Cluster of Excellence Balance of the Microverse.
It has also been shown that the creation of a data management plan (DMP) is a very useful tool for involving project participants at an early stage and increasing awareness regarding the various aspects of data management. A DMP also serves as documentation and reference during the course of the project and thus ensures clarity beyond the project lifetime. Software management plans, which are also intended to ensure the documentation, reproducibility, interoperability, and reusability of research software, are also becoming increasingly widespread.
One of the greatest challenges in interdisciplinary collaborative projects is the combined and integrated use of the often highly heterogeneous data that is generated in such settings. The FAIR Guiding Principles published in 2016 have become widely accepted in this context. Data that fulfils the FAIR principles (Findable, Accessible, Interoperable, Re-usable) can be more easily and successfully reused and integrated. This applies in particular to the automated retrieval, interpretation, selection, and visualisation of data. Key requirements are standardised, detailed data descriptions in the form of metadata, the use of persistent identifiers, the use of interoperable formats, the description of access mechanisms (defined interfaces), and the definition of usage rights in the form of licences.
Great efforts have been made in recent years to implement the FAIR principles. At a conceptual level, the FAIR Digital Objects Framework or the concept of data type registries should be mentioned here. Other activities are aimed at linking NFDI and Gaia-X on the basis of the FAIR principles, such as the BMFTR project FAIR Data Spaces, or developing data management platforms that support the FAIR principles. There are now also tools that can be used to determine the “FAIRness” of data, such as F-UJI or the FAIR Evaluation Services. There are also approaches that apply or transfer the FAIR principles to software and workflows.
In addition to the general FAIR principles, there are numerous subject-specific standards for data and metadata, which usually have a higher level of detail and meet the requirements of a specific community. Terminologies, ontologies, or knowledge graphs are often developed within specific communities and linked to data and metadata. These significantly increase the information content and reusability of the data, even across disciplinary boundaries. Automating these processes and alleviating data producers from time-consuming manual data annotation is a challenge and an active field of research. Another active research topic is the reproducibility of entire workflows that document the creation and processing of data and research results.
This is especially important considering, that the tools used to acquire and analyse data are currently characterised by short innovation cycles and will continue to be so in the foreseeable future. Machine learning and artificial intelligence (AI) methods are increasingly being used to analyse the resulting data volumes, and these methods are also constantly being developed and improved as an active area of research.
Innovations in information technology are also helping to store, process, and manage the growing volumes of data in science and business. Object storage is increasingly gaining ground over traditional file systems as a means of storing large amounts of unstructured data. NoSQL databases and triple stores have been established to store structured data. However, classic SQL databases are still being used, for example, for metadata management13. Software functions such as version management, hierarchical storage management, data compression, data encryption, or checksums for data error correction are implemented in various combinations and forms in the available open source solutions and commercial products for data management.
b. Data management – preliminary work. Roman Gerlach heads the Research Data Management (RDM) Helpdesk at FSU Jena. The RDM Helpdesk was founded in 2015 and has been part of the Competence Centre for Digital Research (zedif) at the FSU Jena since 2021. Zedif acts as a central point of contact for research data and research software management at the FSU Jena and supports researchers primarily through consulting and training. In doing so, it collaborates closely with the central service facilities of the FSU Jena. Zedif consists of a multidisciplinary team with many years of experience in various research domains as well as many years of experience in planning, designing, and implementing sustainable research data management in large collaborative projects. This includes both the governance and communication levels, as well as the technical level, with the planning and development of data management platforms and infrastructures. The RDM team also leads the Thuringian Competence Network for Research Data Management (TKFDM) and is actively involved in developments in the German and international research software engineering (RSE) community. In cooperation with the TKFDM, zedif regularly publishes handouts, best practices, and other information material on Zenodo.org. To date, close to 150 entries have been created in this community. The BMFTR project eeFDM (2017–2019) and the sub-project ThWIC-Data of the Thuringian Water Innovation Cluster (ThWIC, 2023–2026) are examples of research projects where R. Gerlach (Z02) has been involved in a principal investigator role. In both projects, components for efficient research data management in collaborative projects and university research institutions were developed and tested. These include questionnaires for requirements assessment, templates for data management plans, training materials, tools, and infrastructure components.
The König-Ries group has extensive expertise and experience in research data management and related topics relevant to the CRC. The group is home to the development of the BEXIS2 data management software, an opensource platform underlying data management in currently around twenty projects or institutions, and an integral part of the NFDI4Biodiversity service catalog. Using BEXIS2, the group provides comprehensive data management services in a variety of large scale-projects, including the DFG priority programme Biodiversity Exploratories, the JenaCluster of Excellence Balance of the Microverse, and CRC AquaDiva, to name a few. From these projects, the groupbrings extensive experience not only in developing and running data management software, but also in data curation,capacity building, and user support. The group has a long-standing involvement in the RDM community through its keyroles in NFDI4Biodiversity and its predecessor GFBio and can leverage these networks for work in the CRC. Beyond these more service-oriented activities, in order to improve FAIRness of research data, the group has investigated factors influencing reproducibility, contributed to data harmonisation approaches, and developed semantic webbased approaches to knowledge graph creation and (semi-)automatic data annotation.
Like other collaborative scientific projects, this CRC will face the challenge of preserving the increasing amount of data generated by high-throughput methods and powerful recording devices in sequencing, mass spectrometry, and microscopy. The scientists within this CRC will benefit immediately from the expertise of FSU Jena’s RDM HelpDesk and its cooperation with the NFDI LifeSciences HelpDesk. Offered services of the HelpDesks include workshops and training materials in RDM and support in organising, structuring, sharing, preserving, and publishing data and developing software.
c. Bioinformatic services – state of the art. Routine delivery of robust bioinformatic services today hinges on modular, reproducible workflows that users from diverse disciplines can execute with minimal computational burden. In recognition of this, leading bioinformatic cores have adopted workflow management languages – most prominently Nextflow and Snakemake – to orchestrate complex analysis pipelines. Nextflow’s dataflow model allows dynamic parallelisation and seamless scaling from local workstations to high-performance computing (HPC) clusters or cloud environments, while Snakemake’s Python-based rule definitions automatically track file dependencies and facilitate incremental builds. Both systems integrate natively with container technologies – Docker for general Linux environments and Singularity for HPC compatibility – ensuring that every software dependency is encapsulated in a versioned image, thereby guaranteeing that an analysis run today will give identical results years hence. In parallel, modern package managers like Conda and its faster variant, Mamba, have become essential for managing bioinformatic software stacks. By defining reproducible environments via YAML specification files, Conda ensures that all library versions and executables remain consistent across installations. Many core facilities now provide Conda “environment” recipes alongside container images, thus offering users the choice of lightweight local installations or fully containerised deployments. In practice, a pipeline might be defined in Nextflow, call tools installed via Conda/Mamba, and run inside a Singularity container on an HPC cluster, maximising reproducibility, flexibility, and ease of maintenance.
Multi-omics research – simultaneously integrating data from genomics, transcriptomics, proteomics, and metabolomics – demands validated, well-documented preprocessing pipelines. For RNA-seq, current best practice involves raw read quality control (FastQC), adapter trimming (fastp or Trimmomatic), alignment (STAR or HISAT2), quantification (Salmon or featureCounts), and differential expression analysis (DESeq2, edgeR or limma/voom). Each step benefits from container or Conda-based deployment: for instance, the nf-core RNA-seq pipeline bundles all dependencies in Docker images while providing Conda recipes for local testing. Likewise, proteomics pipelines often combine MaxQuant or MSFragger within containerised frameworks, coupled with statistical analysis or MSstats. Metabolomics workflows leverage tools like XCMS or MetaboAnalyst for data (pre-) processing and Sirius for downstream metabolite identification, and are often integrated into Snakemake or Nextflow pipelines for end-to-end reproducibility.
d. Bioinformatic services – preliminary work. The Bioinformatics Core Facility (BiC) at FSU Jena, led by PI E. Barth, exemplifies both methodological innovation and practical competence in developing and disseminating bioinformatic tools that are directly applicable to virus research. At the forefront of the BiC’s portfolio are methods explicitly targeted at virus bioinformatics challenges, for example VIDHOP, a deep-learning pipeline for virus host prediction from short genomic fragments2, which demonstrates the group’s ability to build robust ML models that operate on incomplete or noisy sequence data; and EpiDope, a convolutional neural network for linear B-cell epitope prediction, which supports functional annotation of virus proteins and downstream vaccine-design efforts. Complementing these virus-centric tools, members of the BiC have produced assay- and primer-centric pipelines such as ConsensusPrime, which automates consensus primer design for multiplex assays (demonstrated on MRSA resistance and virulence loci), and AssayBLAST, which performs in silico evaluation of molecular multiparameter
assays to assess specificity and coverage. Beyond virus host attribution and assay design, the facility has developed methods that extend its reach across sequencing modalities and comparative genomics; for example, DiffMONT provides workflows for detecting differentially methylated regions from long-read data, and SweetSynteny enables analysis and visualisation of microsynteny across genomes. Taken together, these tools illustrate the BiC’s breadth – from ML-based virus inference and epitope mapping to assay validation, differential DNA methylation, and comparative synteny analyses – and they are consistently engineered for reproducibility, distribution, and integration. In practice, the BiC packages tools with Conda/Mamba environment recipes and container images (Docker/Singularity), as well as version-control pipelines in Git, and integrates them into Nextflow/Snakemake workflows, which will greatly simplify their uptake by CRC partners and ensures reliable deployment across HPC and cloud infrastructures. This track record of tool development, containerisation, and pipeline integration makes the BiC particularly well-suited to harden CRC prototypes into maintainable, user-friendly services that the consortium and the wider research community can reuse. Further, the BiC has led and supported a broad portfolio of multi-omics projects (transcriptomics, small-RNA, epigenomics, metabolomics, and proteomics), thereby showing that the facility can both develop methods and apply them robustly to heterogeneous, biologically complex data. This capacity is particularly relevant for the CRC, since standardised, reproducible preprocessing and analysis services must be supplied for datasets that vary in modality, quality, and experimental design.
The BiC is uniquely qualified for this task: First, the BiC has experience with virus-centric datasets and with analytical situations that mimic the “early-outbreak” or low-replicate conditions commonly encountered in virology. In the comparative filovirus study, the BiC members were part of the team that analysed Ebola and Marburg virus infections in human and bat cells and derived pathway and transcription-factor signatures despite limited biological replication. The study explicitly demonstrated appropriate quality control, conservative modelling, and cautious interpretation in pilot studies that will transfer directly to the CRC. Equally, functional characterisation of allelic variants of the human antiviral protein MxA (myxovirus resistance protein A) provided mechanistic insight into how sequence variation modulates antiviral activity, illustrating the BiC’s ability to combine molecular assays with rigorous computational analysis to answer virus-relevant functional questions.
Second, BiC members have experience in integrative multi-omics work. The facility has co-authored studies that combine metabolomics and transcriptomics to elucidate interspecies metabolic interactions (for example, microalgal co-culture studies or plant-microbe interactions), demonstrating proficiency in LC-MS feature processing, annotation workflows, and joint statistical modelling of orthogonal data types. Complementary projects on noncoding RNAs (ncRNAs), including ncRNA annotation, evolution, and transcription analysis, show that the BiC can implement RNA-specific preprocessing, differential-expression statistics, and downstream pathway mapping; these skills are operationalised in the BiC’s sRNA analysis pipelines, toolsets, and statistical models (e.g. MeRDE, BayHunter).
Third, the BiC’s hands-on experience with long-read and nanopore technologies (both method reviews and application papers, including nanopore mapping of retrotransposon integration sites1) underlines the group’s ability to manage modality-specific challenges: base-calling noise, methylation calling, adaptive sampling, and the distinct quality control/normalisation steps required for long-read genomics, transcriptomics, and epigenomics. This expertise supports the mandate to deliver robust, modality-aware preprocessing for both short- and long-read datasets, and to advise CRC partners on optimal library strategies and downstream computational choices. Last, the BiC’s output spans organismal biology, clinical genomics, and environmental microbiology, including microbial, virus, and transcriptome integrative analyses, which attests to the facility’s ability to adapt pipelines across taxa, sequencing platforms, and experimental designs. Taken together, these studies (tool engineering, virusspecific analyses, ncRNA and multi-omics projects, and long-read expertise) document that the BiC is not only capable of supporting state-of-the-art computational method development, but also of operationalising them as reproducible, well-documented services. In summary, the BiC is prepared to provide harmonised preprocessing, statistically guarded defaults for low-replicate studies, modality-specific pipelines, and validated assay workflows that enable meaningful, comparable downstream integration across the consortium.
e. Data integration in the VirJenDB – state of the art. Metadata, or data that describes primary data, plays a central role in integrating results across different omics techniques. This integration can be achieved through the application of controlled vocabularies from ontologies, the use of common databases for annotation, and leveraging established file formats for different data types. For sequence data deposition, repositories such as the European Nucleotide Archive (ENA) and the NCBI GenBank adopt open, community-driven standards to model submitted datasets. For example, the most relevant community-driven standards for virus research include the Genome Standards Consortium (GSC), Minimum Information about an Uncultivated Virus Genome (MIUViG), and Minimal Information about a Genome Sequence: Virus (MIGSVi) packages. Moreover, minimal information standards have been established for transcriptomics, proteomics, and metabolomics data, such as the MIAME (Minimum Information About a Microarray Experiment) and mzML. Shared ontology resources providing additional semantic structure across virus omics datasets include the Gene Ontology (GO), IntEnz, KEGG-Virus, PDBeChem, ChEMBL, Disease Ontology, and Virus Orthologous Groups (VOGs). These standards organise metadata into modular categories such as sample collection, protocols, consent, and provenance, which can then be linked via permanent identifiers. Such linkage enables the integration of genomics, transcriptomics, proteomics, and metabolomics datasets in cross-disciplinary projects. Integration across project, experiment, and sample levels can be demonstrated by data management tools such as the NFDI-supported biodiversity platform BEXIS2.
Multimodal integration of metadata, spectral, imaging, and sequencing data is currently driven by advances in cancer, drug development, and microbiome research. In these fields, metadata modelling and advanced techniques are used to integrate high-dimensional datasets for applications such as tumour subtyping, metabolite localisation, and spatial microenvironment mapping, respectively. Metadata anchors datasets with cross-modality descriptors such as sample collection, experimental design, taxonomy, host species, and infection conditions; sequencing can track virus diversity and responses; spectral mass spectrometry can reveal proteomic and metabolomic changes; and imaging (cryo-EM, fluorescence, live-cell) can add spatial and temporal resolution. The OMERO platform enables project and data management of microscopy images, including integration with Galaxy bioinformatic workflows to combine omics and imaging. Formats such as the NFDI4Bioimage-supported OME-Zarr are increasingly used to capture imaging outputs with modelled metadata. Both the Jena Microverse Imaging Center and the Jena Leibniz-HKI already operate OMERO servers.
Recent developments in data and workflow integration have coalesced into powerful, embedded research infrastructures, combining advances in technology, processing power, and adoption of the FAIR principles. For example, the web-accessible analysis platform BV-BRC enables virus bioinformatic workflows to be run in a private workbench. Further, the US National Microbiome Data Collective analysis portal NMDC-Edge demonstrates the central use of standards and formats for microbiome data integration and analysis. Several virus- and pathogen-specific portals have been developed in the past few years, driven by the large amount of data produced on SARS-CoV-2 during the 2020 pandemic and onwards. For example, the NCBI Virus and the EMBL-EBI/ELIXIR Pathogens Portal provide access and browsing of NCBI GenBank and RefSeq virus and pathogen sequences and metadata, respectively. Further, efforts have been made by the large repositories to facilitate finding, browsing, and downloading of genomics data and metadata, such as ongoing development of the NCBI Datasets projects. In packaging metadata with their data, analyses, and workflows, RO-Crates is an NFDI-supported structured package for sharing research data, linking files, analyses, datasets, tools and publications.
f. Data integration with the VirJenDB– preliminary work. Within the NFDI4Microbiota consortium, M. Marz (A04) and N. Cassman (Z02) have led development of VirJenDB, the Virus database based at FSU Jena, to provide a FAIR and Open portal to reuse, manage, analyse, share and improve data and metadata on all viruses. To create the dataset underlying the database, as of Sept 2025, 11 sources of metadata and genomic standards were mapped: NCBI Virus 1.0 schema, BV-BRC results table, Genomic Standards Consortium (GSC) Miuvig, GSC MigsVi, ENA Influenza virus reporting standard checklist, ENA virus pathogen reporting standard checklist, RKI, ICTV Virus Metadata Resource and Master Species List, PubMed, NCBI Taxonomy, and ViralZone. Overall, around 200 metadata fields were harvested, and 86 fields were subjected to at least one round of curation, including several host fields, resulting in the current VirJenDB data model. Further, five sources of publicly available virus sequences were harvested: BV-BRC, NCBI GenBank, and RefSeq (NCBI Virus), a catalogue of prophages predicted by the tool PhiSpy, IMG/VR, and Phage & Host Daily. About 15.4 million sequences have been ingested, with each entry receiving a unique VirJenDB identifier and linked to associated metadata. To create informative subsets of the full dataset, the sequences were processed with a dereplication and clustering workflow using mmseqs linclust and Vclust.
The database is developed as an OpenStack project consisting of several instances on the NFDI4Microbiota member resource, the de.NBI Cloud. The VirJenDB source code is managed using the Git version control system and stored in the VirJenDB GitHub repository. The sequence data is stored on the data orchestration engine (Aruna) as well as one Uni Jena server. The NFDI4Microbiota workflow management system CLoWM currently features several omics workflows relevant to the CRC, such as the nf-core/rnaseq, and is currently being integrated with Aruna and VirJenDB.
The VirJenDB provides a user-friendly web portal developed with continuous feedback from the virus research community via surveys at conferences and personal interviews. Major features of the portal include search, browse, and API access to the dataset of sequences, clusters, and metadata. ElasticSearch provides a powerful search engine while RestAPI and SwaggerUI allow for programmatic access. Further, summary statistics and visualisations are continuously improved. For the CRC, a private workbench is being developed to provide access to a project-specific management and analysis environment, including support for data integration and exploratory visualisations of the CRC tool outputs. The VirJenDB platform is intended to focus community curation efforts and enrich repository submissions of cross-disciplinary virus datasets through extending genomic standards, thereby bridging the eukaryotic and bacteriophage research communities. These aligned aims and features make the NFDI4Microbiota database the ideal infrastructure hub to integrate the cross-disciplinary CRC research outputs and to streamline the unification of the CRC tools in the third funding period.
Project Overview
The Z-Project INFormation, INFormatics, and INFrastructure will provide the essential data backbone for the CRC VirusREvolution. It will drive consortium-wide research by providing unified data workflows that support interoperability and reproducibility in line with the Open Science and FAIR principles.
Our objectives are threefold: (1) to ensure consistent and reproducible processing of all used and generated data across the CRC; (2) to develop and maintain shared infrastructure for data integration, annotation, and dissemination; and (3) to deploy analytical tools in collaboration with CRC subprojects and the broader virology community. The project encompasses six coordinated work packages:
- WP 1 and WP 2 establish the CRC-wide data management strategy and semantic metadata frameworks.
- WP 3 extends the VirJenDB portal and develops it towards a central integration and access point for virus data generated in the CRC.
- WP 4 provides core bioinformatic services and transforms prototype tools into usable pipelines.
- WP 5 delivers curated reference genomes and annotations for all viruses used in the CRC VirusREvolution.
- WP 6 integrates multi-omics and spectral data to generate predictive models of virus-host interaction.
By harmonising data processing and tool development across the consortium, Z02 ensures that scientific findings are comparable, reusable, and accessible, both within the CRC and for the broader research community. It forms the foundation for cross-project collaboration, long-term data stewardship, and sustained impact beyond the funding period.
Work Packages (WP):
- WP 1: Data management strategy (Gerlach/König-Ries)
- WP 2: Semantic description and publication of research objects (König-Ries/Gerlach/Cassman)
- WP 3: Connecting CRC-specific data, tools, and visualisations within VirJenDB (Cassman)
- WP 4: Fundamental bioinformatic services (Barth)
- WP 5: Bioinformatics workflows for the model viruses (Barth/Cassman)
- WP 6: Integration of transcriptomics, metabolomics, and proteomics data of the model viruses (Barth/Cassman)
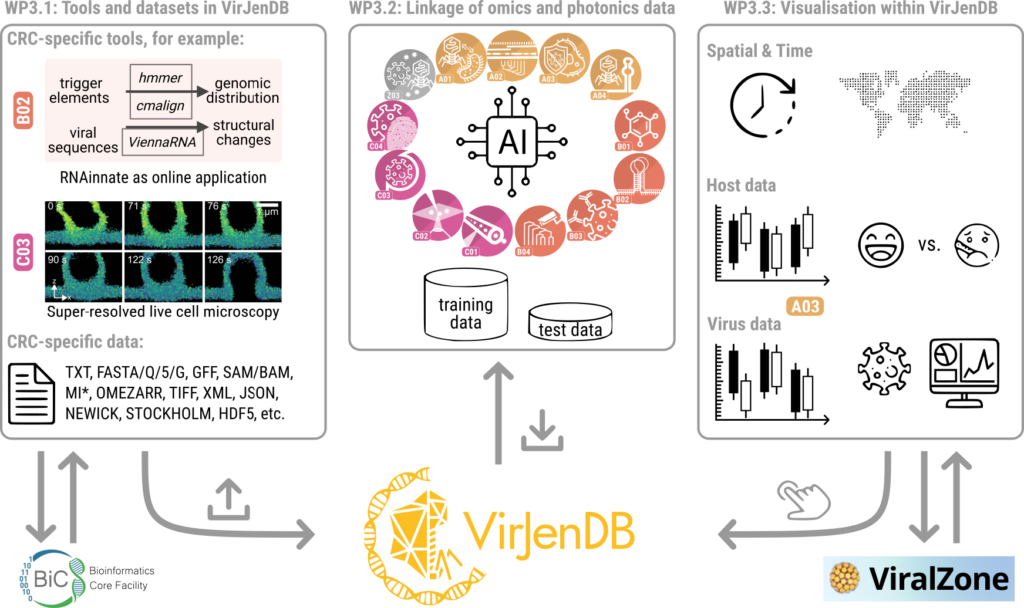
WP 3 workflow for data integration and implementation in the VirJenDB.
Team Members



PhD Z01 1
PhD Student
2025
Saghaei, Shahram; Siemers, Malte; Ossetek, Kilian L; Richter, Stephan; Edwards, Robert A; Roux, Simon; Zielezinski, Andrzej; Dutilh, Bas E; Marz, Manja; Cassman, Noriko A
VirJenDB: a FAIR (meta) data and bioinformatics platform for all viruses Journal Article
In: Nucleic Acids Research, pp. gkaf1224, 2025.
@article{saghaei2025virjendb,
title = {VirJenDB: a FAIR (meta) data and bioinformatics platform for all viruses},
author = {Shahram Saghaei and Malte Siemers and Kilian L Ossetek and Stephan Richter and Robert A Edwards and Simon Roux and Andrzej Zielezinski and Bas E Dutilh and Manja Marz and Noriko A Cassman},
year = {2025},
date = {2025-01-01},
urldate = {2025-01-01},
journal = {Nucleic Acids Research},
pages = {gkaf1224},
publisher = {Oxford University Press},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2023
Ritsch, Muriel; Cassman, Noriko A; Saghaei, Shahram; Marz, Manja
Navigating the landscape: a comprehensive review of current virus databases Journal Article
In: Viruses, vol. 15, no. 9, pp. 1834, 2023.
@article{ritsch2023navigating,
title = {Navigating the landscape: a comprehensive review of current virus databases},
author = {Muriel Ritsch and Noriko A Cassman and Shahram Saghaei and Manja Marz},
year = {2023},
date = {2023-01-01},
urldate = {2023-01-01},
journal = {Viruses},
volume = {15},
number = {9},
pages = {1834},
publisher = {MDPI},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2021
Mock, Florian; Viehweger, Adrian; Barth, Emanuel; Marz, Manja
VIDHOP, viral host prediction with deep learning Journal Article
In: Bioinformatics, vol. 37, no. 3, pp. 318–325, 2021.
@article{mock2021vidhop,
title = {VIDHOP, viral host prediction with deep learning},
author = {Florian Mock and Adrian Viehweger and Emanuel Barth and Manja Marz},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
journal = {Bioinformatics},
volume = {37},
number = {3},
pages = {318–325},
publisher = {Oxford University Press},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Chamanara, Javad; Gaikwad, Jitendra; Gerlach, Roman; Algergawy, Alsayed; Ostrowski, Andreas; König-Ries, Birgitta
BEXIS2: A FAIR-aligned data management system for biodiversity, ecology and environmental data Journal Article
In: Biodiversity Data Journal, vol. 9, pp. e72901, 2021.
@article{chamanara2021bexis2,
title = {BEXIS2: A FAIR-aligned data management system for biodiversity, ecology and environmental data},
author = {Javad Chamanara and Jitendra Gaikwad and Roman Gerlach and Alsayed Algergawy and Andreas Ostrowski and Birgitta König-Ries},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
journal = {Biodiversity Data Journal},
volume = {9},
pages = {e72901},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Samuel, Sheeba; König-Ries, Birgitta
Understanding experiments and research practices for reproducibility: an exploratory study Journal Article
In: PeerJ, vol. 9, pp. e11140, 2021.
@article{samuel2021understanding,
title = {Understanding experiments and research practices for reproducibility: an exploratory study},
author = {Sheeba Samuel and Birgitta König-Ries},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
journal = {PeerJ},
volume = {9},
pages = {e11140},
publisher = {PeerJ Inc.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Löffler, Felicitas; Wesp, Valentin; König-Ries, Birgitta; Klan, Friederike
Dataset search in biodiversity research: Do metadata in data repositories reflect scholarly information needs? Journal Article
In: PloS one, vol. 16, no. 3, pp. e0246099, 2021.
@article{loffler2021dataset,
title = {Dataset search in biodiversity research: Do metadata in data repositories reflect scholarly information needs?},
author = {Felicitas Löffler and Valentin Wesp and Birgitta König-Ries and Friederike Klan},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
journal = {PloS one},
volume = {16},
number = {3},
pages = {e0246099},
publisher = {Public Library of Science San Francisco, CA USA},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2020
Srivastava, Akash; Barth, Emanuel; Ermolaeva, Maria A; Guenther, Madlen; Frahm, Christiane; Marz, Manja; Witte, Otto W
Tissue-specific gene expression changes are associated with aging in mice Journal Article
In: Genomics, proteomics & bioinformatics, vol. 18, no. 4, pp. 430–442, 2020.
@article{srivastava2020tissue,
title = {Tissue-specific gene expression changes are associated with aging in mice},
author = {Akash Srivastava and Emanuel Barth and Maria A Ermolaeva and Madlen Guenther and Christiane Frahm and Manja Marz and Otto W Witte},
year = {2020},
date = {2020-01-01},
urldate = {2020-01-01},
journal = {Genomics, proteomics & bioinformatics},
volume = {18},
number = {4},
pages = {430–442},
publisher = {Oxford University Press},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2019
Barth, Emanuel; Srivastava, Akash; Stojiljkovic, Milan; Frahm, Christiane; Axer, Hubertus; Witte, Otto W; Marz, Manja
Conserved aging-related signatures of senescence and inflammation in different tissues and species Journal Article
In: Aging (Albany NY), vol. 11, no. 19, pp. 8556, 2019.
@article{barth2019conserved,
title = {Conserved aging-related signatures of senescence and inflammation in different tissues and species},
author = {Emanuel Barth and Akash Srivastava and Milan Stojiljkovic and Christiane Frahm and Hubertus Axer and Otto W Witte and Manja Marz},
year = {2019},
date = {2019-01-01},
urldate = {2019-01-01},
journal = {Aging (Albany NY)},
volume = {11},
number = {19},
pages = {8556},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2012
Cassman, Noriko; Prieto-Davó, Alejandra; Walsh, Kevin; Silva, Genivaldo GZ; Angly, Florent; Akhter, Sajia; Barott, Katie; Busch, Julia; McDole, Tracey; Haggerty, J Matthew; others,
Oxygen minimum zones harbour novel viral communities with low diversity Journal Article
In: Environmental microbiology, vol. 14, no. 11, pp. 3043–3065, 2012.
@article{cassman2012oxygen,
title = {Oxygen minimum zones harbour novel viral communities with low diversity},
author = {Noriko Cassman and Alejandra Prieto-Davó and Kevin Walsh and Genivaldo GZ Silva and Florent Angly and Sajia Akhter and Katie Barott and Julia Busch and Tracey McDole and J Matthew Haggerty and others},
year = {2012},
date = {2012-01-01},
urldate = {2012-01-01},
journal = {Environmental microbiology},
volume = {14},
number = {11},
pages = {3043–3065},
publisher = {Wiley Online Library},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
0000
Axtmann, Alexandra
”Wir bringen die breite Basis mit” – Gemeinsames Plädoyer für eine enge Einbindung der Landesinitiativen für Forschungsdatenmanagement in die Nationale Forschungsdateninfrastruktur. Journal Article
In: 0000.
@article{axtmannwir,
title = {”Wir bringen die breite Basis mit” – Gemeinsames Plädoyer für eine enge Einbindung der Landesinitiativen für Forschungsdatenmanagement in die Nationale Forschungsdateninfrastruktur.},
author = {Alexandra Axtmann},
publisher = {Deutsche Nationalbibliothek},
keywords = {},
pubstate = {published},
tppubtype = {article}
}